
Un nouveau modèle d'IA pour renforcer l'anonymisation des données de Santé
MARDI 01 JUIN 2021 Soyez le premier à réagir
Soyez le premier à réagirLes algorithmes d'IA apportent chaque jour la preuve de leur efficacité diagnostique mais, pour entraîner ces algorithmes, il faut accéder des données médicales protégées. Une équipe de chercheurs de la Technical University of Munich a développé une technologie qui garantit la protection des données personnelles des patients lors de la formation d’algorithmes. Il est maintenant utilisé pour la première fois dans un algorithme qui identifie la pneumonie sur les images radiographiques pédiatriques.

La médecine numérique ouvre des possibilités entièrement nouvelles, notamment les nouveaux algorithmes d'IA dont l’efficacité dépend de la quantité et de la qualité des données utilisées pour les former.
Des failles possibles dans l'anonymisation de données de Santé
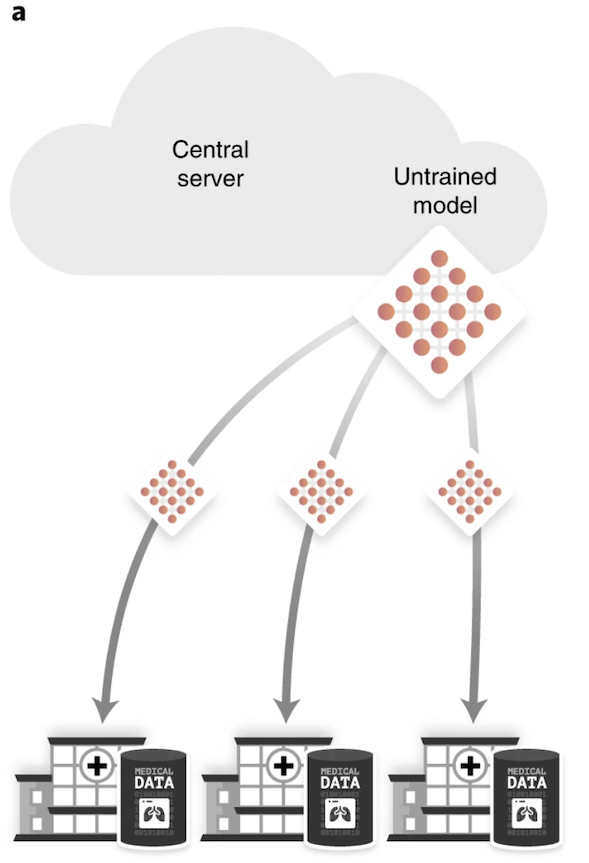 Pour maximiser le pool de données, il est courant de partager les données des patients entre les centres de radiologie en envoyant des copies des bases de données aux sociétés où l'algorithme est formé. À des fins de protection des données, ces dernières sont généralement soumises à des processus d'anonymisation et de pseudonymisation qui n’échappent pas, quelquefois, à la critique. « Certains processus d’anonymisation se sont souvent avérés inadéquats en termes de protection des données de santé des patients », remarque le Dr Daniel Rueckert, Professeur d’intelligence artificielle en soins de santé et en médecine à la Technical University of Munich (TUM).
Pour maximiser le pool de données, il est courant de partager les données des patients entre les centres de radiologie en envoyant des copies des bases de données aux sociétés où l'algorithme est formé. À des fins de protection des données, ces dernières sont généralement soumises à des processus d'anonymisation et de pseudonymisation qui n’échappent pas, quelquefois, à la critique. « Certains processus d’anonymisation se sont souvent avérés inadéquats en termes de protection des données de santé des patients », remarque le Dr Daniel Rueckert, Professeur d’intelligence artificielle en soins de santé et en médecine à la Technical University of Munich (TUM).
Pour résoudre ce problème, une équipe interdisciplinaire de la TUM a travaillé avec des chercheurs de l'Imperial College de Londres et de l'organisation à but non lucratif OpenMined pour développer une combinaison unique d’aide au diagnostic basée sur l'IA d'images radiologiques qui protègent la confidentialité des données. Dans un article publié dans Nature Machine Intelligence, l'équipe a montré que son application fonctionne grâce à un algorithme de deep learning qui aide à classer les signes radiologiques de pneumonie dans les radiographies pulmonaires des enfants.
Des modèles formés dans les centres de radiologie avant d'être transférés
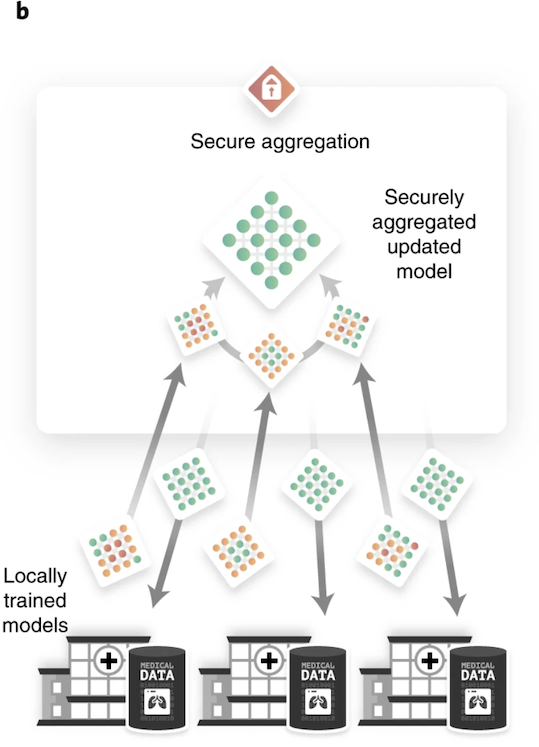 « Nous avons testé nos modèles auprès de radiologues spécialisés. Dans certains cas, les modèles ont montré une précision comparable ou meilleure dans le diagnostic de divers types de pneumonie chez les enfants », poursuit le Professeur Marcus R. Makowski, directeur du département de radiologie diagnostique et interventionnelle du Klinikum rechts der Isar de la TUM. Le chef de projet et premier auteur de l’étude, le Dr Georgios Kaissis de l'Institut d'informatique médicale, de statistique et d'épidémiologie de la TUM, estilme quant à lui que, « pour que les données des patients soient protégées, il ne faut pas qu’elles quittent le site où elles sont collectées. Pour notre algorithme, nous avons utilisé l'apprentissage fédéré, dans lequel l'algorithme de deep learning est partagé - et non les données. »
« Nous avons testé nos modèles auprès de radiologues spécialisés. Dans certains cas, les modèles ont montré une précision comparable ou meilleure dans le diagnostic de divers types de pneumonie chez les enfants », poursuit le Professeur Marcus R. Makowski, directeur du département de radiologie diagnostique et interventionnelle du Klinikum rechts der Isar de la TUM. Le chef de projet et premier auteur de l’étude, le Dr Georgios Kaissis de l'Institut d'informatique médicale, de statistique et d'épidémiologie de la TUM, estilme quant à lui que, « pour que les données des patients soient protégées, il ne faut pas qu’elles quittent le site où elles sont collectées. Pour notre algorithme, nous avons utilisé l'apprentissage fédéré, dans lequel l'algorithme de deep learning est partagé - et non les données. »
« Nos modèles ont été formés dans différents hôpitaux en utilisant les données locales puis nous ont été renvoyés. Ainsi, les propriétaires de données n'ont pas eu à les partager leurs données et conservent un contrôle total », explique le premier auteur Alexander Ziller, chercheur à l'Institut de radiologie.
Pour éviter l'identification des institutions où l'algorithme a été formé, l'équipe a appliqué une autre technique, l'agrégation sécurisée. « Nous avons combiné les algorithmes sous forme cryptée et ne les avons décryptés qu'après les avoir formés avec les données de toutes les institutions participantes, explique Kaissis. Et pour garantir une « confidentialité différentielle », c'est-à-dire pour empêcher que les données individuelles des patients ne soient séparées des enregistrements de données, les chercheurs ont utilisé une troisième technique lors de la formation de l'algorithme. « En fin de compte, les corrélations statistiques peuvent être extraites des enregistrements de données, mais pas les contributions des personnes individuelles », explique Kaissis.
Une méthode qui favorise la coopération entre les institutions et la généralisation de l'IA
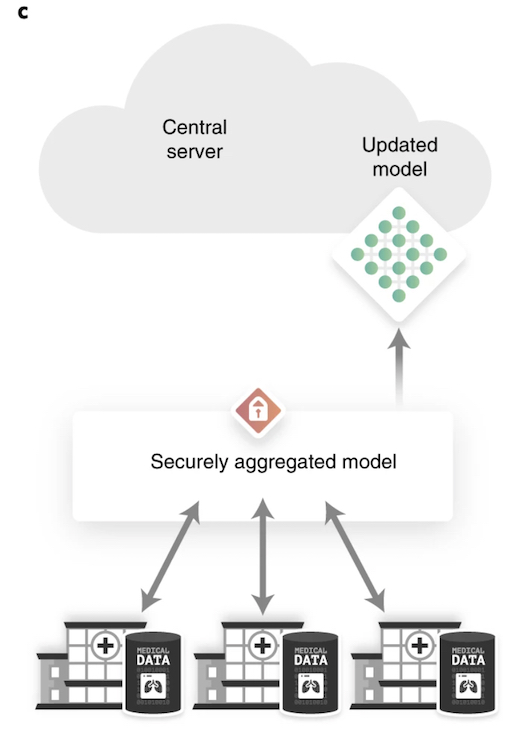 « Nos méthodes ont été appliquées dans d'autres études, souligne Daniel Rueckert. Mais nous n'avons pas encore vu d'études à grande échelle utilisant des données cliniques réelles. Grâce au développement ciblé de technologies et à la coopération entre spécialistes en informatique et en radiologie, nous avons réussi à former des modèles qui fournissent des résultats précis tout en répondant à des normes élevées de protection des données et de confidentialité. » Les scientifiques ajoutent que leur méthode peut être appliquée à d'autres données médicales que la radiographie, notamment à la parole et au texte.
« Nos méthodes ont été appliquées dans d'autres études, souligne Daniel Rueckert. Mais nous n'avons pas encore vu d'études à grande échelle utilisant des données cliniques réelles. Grâce au développement ciblé de technologies et à la coopération entre spécialistes en informatique et en radiologie, nous avons réussi à former des modèles qui fournissent des résultats précis tout en répondant à des normes élevées de protection des données et de confidentialité. » Les scientifiques ajoutent que leur méthode peut être appliquée à d'autres données médicales que la radiographie, notamment à la parole et au texte.
La combinaison des derniers processus de protection des données facilitera également la coopération entre les institutions, comme l'équipe l'a montré dans un article publié dans Nature Machine Intelligence en 2020. Leur méthode d'IA préservant la vie privée peut surmonter les obstacles éthiques, juridiques et politiques - ouvrant ainsi la voie à utilisation généralisée de l'IA. Et cela est extrêmement important pour la recherche, en particulier sur les maladies rares.
Les scientifiques sont convaincus que leur technologie, en sauvegardant la sphère privée des patients, peut apporter une contribution importante à l'avancement de la médecine numérique.
Bruno Benque avec TUM