

Des modèles pertinents de deep learning pour la radiographie thoracique
Selon une étude publiée dans la revue Radiology, le deep learning peut détecter des résultats de radiographie thoracique cliniquement significatifs aussi efficacement que des radiologues expérimentés. Les chercheurs rapportent que leurs résultats pourraient constituer une ressource précieuse pour le développement futur de modèles d’intelligence artificielle pour la radiographie thoracique.
La radiographie thoracique a, depuis longtemps atteint ses limites en termes de diagnostic, notamment depuis la généralisation du scanner. Il n’empêche que cet examen a toujours son utilité et reste celui qui est le plus pratiqué dans le monde.
Des modèles combinant des données du Royaume-Uni et d’Inde
 « Nous avons constaté que l’interprétation des radiographies du thorax est très subjective, a déclaré Shravya Shetty, responsable de l’ingénierie chez Google Health à Palo Alto, en Californie et co-auteur d’une étude publiée dans la Revue Radiology. Une variabilité significative entre les lecteurs et une sensibilité non optimale pour la détection de résultats cliniques importants peuvent limiter son efficacité. » Le deep learning a le potentiel d'améliorer l'interprétation des radiographies du thorax, mais il a aussi des limites. Par exemple, les résultats obtenus d'un groupe de patients ne peuvent pas toujours être généralisés à la population en général.
« Nous avons constaté que l’interprétation des radiographies du thorax est très subjective, a déclaré Shravya Shetty, responsable de l’ingénierie chez Google Health à Palo Alto, en Californie et co-auteur d’une étude publiée dans la Revue Radiology. Une variabilité significative entre les lecteurs et une sensibilité non optimale pour la détection de résultats cliniques importants peuvent limiter son efficacité. » Le deep learning a le potentiel d'améliorer l'interprétation des radiographies du thorax, mais il a aussi des limites. Par exemple, les résultats obtenus d'un groupe de patients ne peuvent pas toujours être généralisés à la population en général.
Les chercheurs de Google Health ont développé des modèles de deep learning dans ce cadre, permettant de surmonter certaines de ces limitations. Ils ont utilisé deux grands ensembles de données pour développer, former et tester les modèles. Le premier ensemble de données comprenait plus de 750 000 images provenant de cinq hôpitaux en Inde, tandis que le second ensemble comprenait 112 120 images mises à la disposition du public par le National Institutes of Health (NIH).
Des résultats identiques aux radiologues pour certaines images significatives
Un groupe de radiologues s'est réuni pour créer les annotations d’images pour certaines anomalies visibles sur les radiographies thoraciques utilisées pour former les modèles. « L'interprétation des radiographies thoraciques est souvent une évaluation qualitative, ce qui pose problème du point de vue du deep learning, poursuit Daniel Tse, chef de produit chez Google Health. En utilisant un champ plus large et plus diversifié de données de radiographie thoracique et en les évaluant par panel, nous avons pu produire des modèles plus fiables. »
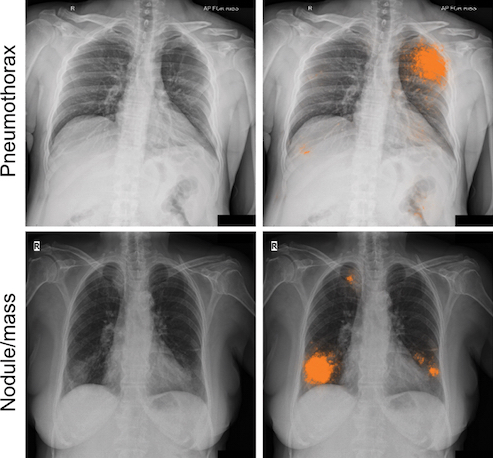
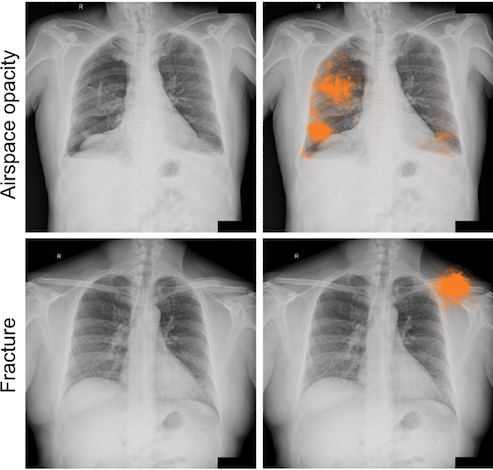 Les tests des modèles de deep learning ont montré que leurs résultats étaient comparables à ceux des radiologues en détectant quatre types d’images significatives sur les radiographies thoraciques de face : fractures, nodules ou masses, opacités et pneumothorax. L’évaluation des radiologues a conduit à un consensus plus évolué des experts sur les annotations utilisées pour le paramétrage du modèle et sur l'évaluation de la performance. Le consensus global est passé d’un peu plus de 41% après la lecture initiale à plus de 97% après l’utilisation de la nouvelle cohorte.
Les tests des modèles de deep learning ont montré que leurs résultats étaient comparables à ceux des radiologues en détectant quatre types d’images significatives sur les radiographies thoraciques de face : fractures, nodules ou masses, opacités et pneumothorax. L’évaluation des radiologues a conduit à un consensus plus évolué des experts sur les annotations utilisées pour le paramétrage du modèle et sur l'évaluation de la performance. Le consensus global est passé d’un peu plus de 41% après la lecture initiale à plus de 97% après l’utilisation de la nouvelle cohorte.
Développer des modèles d'intelligence artificielle cliniquement utiles pour la radiographie thoracique
Les techniques d'évaluation de modèle rigoureuses présentent des avantages par rapport aux méthodes existantes, ont déclaré les chercheurs. Tout d’abord parce qu’elles mettent en jeu un vaste ensemble d'images cliniques en milieu hospitalier, par l’échantillonnage d’un ensemble divers de cas ensuite, et enfin parce que des métriques ajustées en fonction de la population donnent des résultats plus représentatifs et comparables. « Nous pensons que l'échantillonnage de données utilisé dans ce travail permet de représenter plus précisément l'incidence de ces affections, a déclaré le Dr Tse. À l'avenir, le deep learning peut constituer une ressource utile pour faciliter le développement continu de modèles d'intelligence artificielle cliniquement utiles pour la radiographie thoracique. »
L’équipe de recherche a mis à la disposition des chercheurs les étiquettes d’évaluation des milliers d’images du NIH à l’adresse suivante: https://cloud.google.com/healthcare/docs/resources/public-datasets/nih-chest#. additional_labels. « La base de données du NIH est une ressource très importante, mais les étiquettes actuelles sont bruyantes, ce qui rend difficile l'interprétation des résultats publiés sur ces données, a déclaré Shetty. Nous espérons que la publication de nos étiquettes contribuera à la poursuite des recherches dans ce domaine. »
SUR LE MÊME THÈME


Une checklist pour l'élaboration des outils d'IA en imagerie mise à jour
Si les outils et modèles d’intelligence artificielle (IA) sont aujourd’hui largement répandus, leur précision et leur robustesse sont encore inégales. Pour faire évoluer cette discipline, des documents de recommandations relatives à l’élaboration de ces outils font office de référence pour leurs aut...
03/04/2026 -

La radiologie française parle aux européens des apports de l'IA dans l'imagerie d'urgence
Vu dans la newsletter de Mars 2026 publiée par la Société Française de Radiologie (SFR), un retour sur la session “ESR meets France” qui a réuni, à l’occasion de l’European Congress of Radiology (ECR), des experts français et européens autour d’un sujet désormais central pour l’imagerie en soins aig...
01/04/2026 -

L'IA peut-elle jouer un rôle dans le burn-out des radiologues ?
L’IA peut-elle permettre de réduire le burn-out des radiologues ? Il semble que non, si l’on en croit une revue de la littérature publiée dans la Revue European Radiology, qui tente de trouver des preuves des bienfaits de l’IA sur la santé mentale des radiologues. Les chercheurs estiment qu’une meil...
30/03/2026 -

La plateforme ATLAS d'IA en radiologie intègre plus de 230 fiches de modèles
La Radiological Society of North America (RSNA) annonce la présence de plus de 230 fiches de modèles et de jeux de données concernant 31 sous-spécialités dans sa bibliothèque annotée de systèmes d'IA (ATLAS), offrant ainsi à la communauté radiologique les outils nécessaires pour rendre la recherche...
27/03/2026 -

Une solution d'aide au diagnostic validée par la FDA pour le dépistage du cancer du poumon
Median Technologies vient d'annoncer avoir obtenu l’autorisation de la FDA pour eyonis® LCS, le premier logiciel dispositif médical de détection et diagnostic basé sur l’IA pour le dépistage du cancer du poumon.
10/02/2026 -

Un modèle de segmentation des images IRM obtient le Prix Alexander Magulis 2025
Après la tomodensitométrie, c’est au tour des images IRM de bénéficier de la segmentation automatisée. TotalSegmentator MRI, un modèle entraîné à la fois sur des images IRM et TDM, a remporté le Prix Alexander R. Margulis 2025 de la RSNA. Il s’agit d’un outil très précis permettant notamment d’obten...
02/12/2025 -

Un assistant clinique IA qui optimise le workflow médical
Microsoft vient d’annoncer la disponibilité en France de Microsoft Dragon Copilot, un assistant clinique IA conçu pour simplifier la documentation, faciliter la recherche d’informations et automatiser des tâches.
08/10/2025 -

LETTRE D'INFORMATION
Ne manquez aucune actualité en imagerie médicale et radiologie !
Inscrivez-vous à notre lettre d’information hebdomadaire pour recevoir les dernières actualités, agendas de congrès, et restez informé des avancées et innovations dans le domaine.