

IA et imagerie médicale : les biais liés à la gestion des données
Avec l'utilisation croissante de l'intelligence artificielle (IA) en radiologie, il est essentiel de minimiser les biais dans les systèmes de machine learning avant de mettre en œuvre leur utilisation dans des scénarios cliniques réels. C'est ce que suggère un rapport spécial publié dans la revue Radiology: Artificial Intelligence qui cible des pratiques inopérantes relatives à la collecte et la gestion des données
Un rapport d’envergure publié dans la Revue Radiology : artificial intelligence se propose d’identifier et de minimiser les biais pouvant se trouver dans les modèles de machine learning avant leur mise en production dans des conditions cliniques. Il s’agit du premier d'une série de trois rapports, qui décrit les pratiques sous-optimales utilisées dans la phase de traitement des données du développement du système de machine learning et qui présente des stratégies pour les atténuer.
Des modèles de machine learning biaisés par une gestion souvent inopérante des données
« Il existe 12 pratiques sous-optimales qui se produisent pendant la phase de traitement des données du développement d'un système de machine learning, chacune pouvant prédisposer le système à des biais, annonce le Pr Bradley J. Erickson, professeur de radiologie et directeur du laboratoire d'IA de la clinique Mayo, à Rochester -Minnesota, USA -. Si ces biais systématiques ne sont pas reconnus ou quantifiés avec précision, des résultats sous-optimaux s'ensuivront, limitant l'application de l'IA à des scénarios réels. »
 Le Pr Erickson ajoute en préambule que le sujet de la gestion appropriée des données attirait de plus en plus l'attention, mais que les lignes directrices sur la gestion correcte des mégadonnées sont rares. « Les défis réglementaires et les lacunes translationnelles entravent toujours la mise en œuvre du machine learning dans des scénarios cliniques réels, poursuit-il. Cependant, nous nous attendons à ce que la croissance exponentielle des systèmes d'IA en radiologie accélère la suppression de ces barrières. Pour préparer les systèmes de machine learning à l'adoption et à la mise en œuvre clinique, il est essentiel de minimiser les biais. »
Le Pr Erickson ajoute en préambule que le sujet de la gestion appropriée des données attirait de plus en plus l'attention, mais que les lignes directrices sur la gestion correcte des mégadonnées sont rares. « Les défis réglementaires et les lacunes translationnelles entravent toujours la mise en œuvre du machine learning dans des scénarios cliniques réels, poursuit-il. Cependant, nous nous attendons à ce que la croissance exponentielle des systèmes d'IA en radiologie accélère la suppression de ces barrières. Pour préparer les systèmes de machine learning à l'adoption et à la mise en œuvre clinique, il est essentiel de minimiser les biais. »
Un rapport d’expertise qui cible 12 pratiques à améliorer pour valider les modèles d’IA
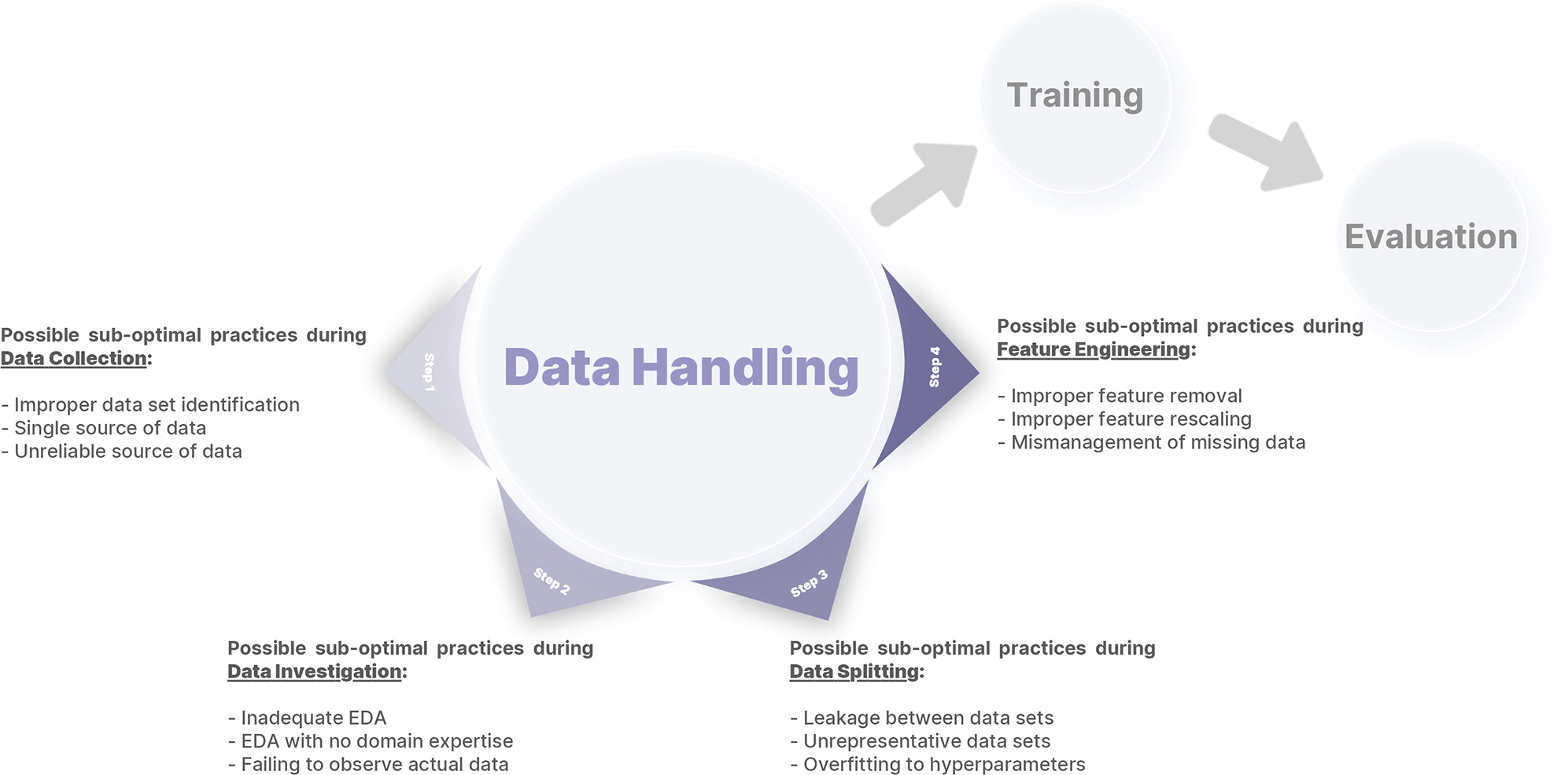
Dans ce rapport, le Pr Erickson et son équipe suggèrent des stratégies d'atténuation pour les 12 pratiques sous-optimales qui se produisent dans les quatre étapes de traitement des données du développement du système d’IA - trois pour chaque étape de traitement des données -.
Concernant la collecte de données, l’identification incorrecte de l'ensemble de données, la source unique de données et la source de données non fiable sont ciblées. Pour l’exploration des données, les chercheurs souhaitent travailler sur l’analyse de données exploratoires inadéquates, de données exploratoires sans expertise dans le domaine ou l’omission d'observer les données réelles.
Pour améliorer le fractionnement des données, le rapport identifie une fuite entre les ensembles de données, des ensembles de données non représentatifs, ainsi qu’un surajustement aux hyperparamètres. Enfin, sur le thème de l’ingénierie des données, les chercheurs font un focus sur la suppression incorrecte des fonctionnalités, leur redimensionnement incorrect ou une mauvaise gestion des données manquantes.
Planification minutieuse de la collecte et collaboration avec des experts de la science des données
Le Pr Erickson trouve d’autre part que les données médicales sont souvent loin d'être idéales pour alimenter les algorithmes de machine learning. « Chacune de ces étapes pourrait être sujette à des biais systématiques ou aléatoires, ajoute-t-il. Il est de la responsabilité des développeurs de gérer avec précision les données dans des scénarios difficiles tels que l'échantillonnage des données, l'anonymisation, l'annotation, l'étiquetage et la gestion des valeurs manquantes. »
Le rapport recommande une planification minutieuse avant la collecte de données incluant un examen approfondi de la littérature clinique et technique, ainsi qu’une collaboration avec une expertise en science des données. « Les équipes de machine learning multidisciplinaires devraient avoir des membres ou des dirigeants possédant à la fois une expertise en science des données et dans le domaine clinique » affirme-t-il.
Pour développer un ensemble de données de formation plus hétérogène, le Pr Erickson et ses co-auteurs suggèrent de collecter des données auprès de plusieurs institutions de différents emplacements géographiques, issues de différents fournisseurs et de différentes époques, ou en incluant des ensembles de données publiques.
Deux autres rapports qui cibleront les phases de développement et d’évaluation des modèles d’IA
« La création d'un système machine learning robuste nécessite que les chercheurs effectuent un travail de détective et recherchent des moyens par lesquels les données peuvent vous tromper, déclare-t-il. Avant de mettre des données dans le module de formation, vous devez les analyser pour vous assurer qu'elles reflètent votre population cible. L'IA ne le fera pas pour vous. Même après une excellente gestion des données, les systèmes d’IA peuvent toujours être sujets à des biais importants. Les deuxième et troisième rapports de cette série publiée dans Radiology se concentreront sur les biais qui se produisent dans les phases de développement et d'évaluation du modèle, ainsi que de reporting.
Ces dernières années, le machine learning a démontré son utilité dans de nombreux domaines de recherche clinique, de la reconstruction d'images à l'amélioration des outils de diagnostic, de pronostic et de surveillance, conclut le Pr Erickson. Cette série de rapports vise à identifier les pratiques erronées lors du développement de du machine learning et à les atténuer autant que possible. »
SUR LE MÊME THÈME

Un modèle économique à trouver pour développer l'IA en imagerie médicale
Catel, coopérative d'intérêt général fondée en 1997 qui rassemble de nombreux acteurs de la e-santé, vient de publier un livre blanc qui traite du modèle économique de l’IA en imagerie médicale.
09/06/2026 -


Les trois principes de base de l'IA explicable
La confiance des professionnels de Santé envers l’IA commence par l’assimilation du fonctionnement des algorithmes, grâce à l’IA explicable. Les trois principes directeurs de cette méthode décrits dans un article de l’American Journal of Roentgenology (AJR), pourraient rassurer les praticiens sur la...
26/05/2026 -

Une checklist pour l'élaboration des outils d'IA en imagerie mise à jour
Si les outils et modèles d’intelligence artificielle (IA) sont aujourd’hui largement répandus, leur précision et leur robustesse sont encore inégales. Pour faire évoluer cette discipline, des documents de recommandations relatives à l’élaboration de ces outils font office de référence pour leurs aut...
03/04/2026 -

La radiologie française parle aux européens des apports de l'IA dans l'imagerie d'urgence
Vu dans la newsletter de Mars 2026 publiée par la Société Française de Radiologie (SFR), un retour sur la session “ESR meets France” qui a réuni, à l’occasion de l’European Congress of Radiology (ECR), des experts français et européens autour d’un sujet désormais central pour l’imagerie en soins aig...
01/04/2026 -

L'IA peut-elle jouer un rôle dans le burn-out des radiologues ?
L’IA peut-elle permettre de réduire le burn-out des radiologues ? Il semble que non, si l’on en croit une revue de la littérature publiée dans la Revue European Radiology, qui tente de trouver des preuves des bienfaits de l’IA sur la santé mentale des radiologues. Les chercheurs estiment qu’une meil...
30/03/2026 -

La plateforme ATLAS d'IA en radiologie intègre plus de 230 fiches de modèles
La Radiological Society of North America (RSNA) annonce la présence de plus de 230 fiches de modèles et de jeux de données concernant 31 sous-spécialités dans sa bibliothèque annotée de systèmes d'IA (ATLAS), offrant ainsi à la communauté radiologique les outils nécessaires pour rendre la recherche...
27/03/2026 -

Une solution d'aide au diagnostic validée par la FDA pour le dépistage du cancer du poumon
Median Technologies vient d'annoncer avoir obtenu l’autorisation de la FDA pour eyonis® LCS, le premier logiciel dispositif médical de détection et diagnostic basé sur l’IA pour le dépistage du cancer du poumon.
10/02/2026 -

LETTRE D'INFORMATION
Ne manquez aucune actualité en imagerie médicale et radiologie !
Inscrivez-vous à notre lettre d’information hebdomadaire pour recevoir les dernières actualités, agendas de congrès, et restez informé des avancées et innovations dans le domaine.