

Limiter les volumes de données grâce au Supervised Contrastive Learning
Dans un travail de recherche publiée récemment dans la Revue Radiology, des chercheurs de Google et Northwestern ont développé une méthode permettant de réduire les exigences de volumes de données à analyser dans les modèles de deep learning (DL) pour la radiographie pulmonaire. Ils ont mis au point pour cela une approche de DL avancé dénommé supervised contrastive learning (SupCon).
L’Intelligence Artificielle est désormais reconnue comme une discipline solide pour apporter une aide à la décision cliniques des radiologues. Mais le volume de données de Santé et et les ressources de calcul importantes que les modèles d’IA nécessitent pour en valider la pertinence représente un frein à son développement.
Le SupCon learning pour réduire les volumes de données nécessaires aux modèles de DL
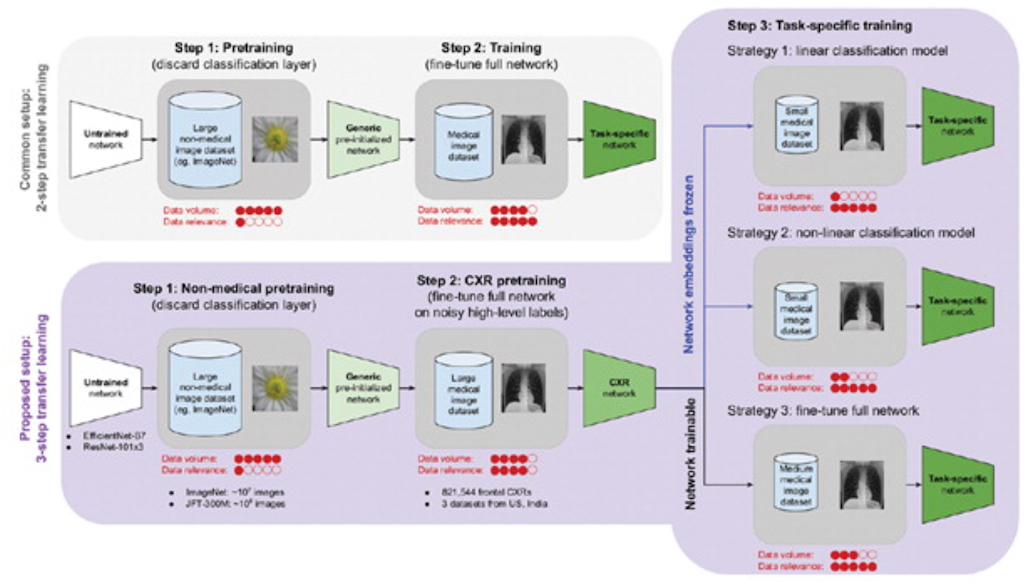
Les contraintes au développement des modèles d’IA peuvent provenir, de plus, des changements rapides susceptibles d’intervenir dans les populations de patients, le COVID-19 étant ici un bon exemple. Une atténuation partielle de ces contraintes consiste en l'apprentissage par transfert, en créant un « réseau générique » sur un grand ensemble de données non médicales, puis en affinant un ensemble de données radiologiques spécifiques à une tâche.
Mais des chercheurs de Google et Northwestern ont travaillé récemment sur une approche permettant de limiter ces flux de données et ont publié leur travail dans la Revue Radiology. En développant le supervised contrastive (SupCon) learning pour l’analyse des radiographies de thorax, ils ont certainement fait passer une étape à la discipline. lls ont ainsi généré des « réseaux radio de thorax » à partir de 821 544 radiographies pulmonaires, puis utilisé ces réseaux comme point de départ pour le développement de modèles deep learning dédiés à 10 tâches de prédiction clinique (telles que l'opacité de l'espace aérien, les fractures, la tuberculose et les résultats COVID-19) à l'aide de 5 ensembles de données comprenant 684 955 radiographies pulmonaires venues d'Inde, des États-Unis et de Chine.
Des performances comparables au DL classique à partir de seulement 45 radiographies pulmonaires
"Notre méthode a permis des performances de prédiction comparables aux modèles DL de pointe dans de multiples tâches cliniques en utilisant aussi peu que 45 radiographies pulmonaires", ont précisé les auteurs.
En pratique, le SupCon learning a aidé à générer des réseaux de radiographies thoraciques à partir de 821 544 radiographies thoraciques qui ont été utilisés comme point de départ pour le développement d'un modèle de DL pour 10 tâches de prédiction en utilisant cinq ensembles de données. Trois configurations de développement de modèles ont été testées (classificateur linéaire, classificateur non linéaire et affinage global du réseau) avec différentes tailles d'ensembles de données allant de huit à 85.
Multiplier les modèles pour couvrir un nombre significatif de situations cliniques
Les chercheurs ont constaté que, dans la majorité des tâches, par rapport à l'apprentissage par transfert à partir d'un ensemble de données non médicales, SupCon a réduit les exigences d'étiquetage jusqu'à 688 fois et amélioré la zone AUC à des tailles d'ensemble de données correspondantes. Au régime de données extrêmement faible, la formation de petits modèles non linéaires en utilisant seulement 45 radiographies thoraciques a donné une ASC de 0,95 (non inférieure à la performance du radiologue) dans la classification de la tuberculose confirmée par la microbiologie. À un régime de données plus modéré, la formation de petits modèles non linéaires en utilisant seulement 528 radiographies thoraciques a donné une ASC de 0,75 pour prédire les résultats graves du COVID-19.
Cette étude montre que le SupCon a permis des performances comparables aux modèles de DL de pointe dans de multiples tâches cliniques en utilisant aussi peu que 45 images et de la considérer comme une méthode prometteuse pour la modélisation prédictive avec l'utilisation de petits ensembles de données ainsi que pour prédire les résultats dans les populations de patients changeantes. Il sera néanmoins nécessaire de multiplier les modèles afin que l’aide à la décision puisse couvrir un nombre significatif de situations cliniques.
SUR LE MÊME THÈME

Un modèle économique à trouver pour développer l'IA en imagerie médicale
Catel, coopérative d'intérêt général fondée en 1997 qui rassemble de nombreux acteurs de la e-santé, vient de publier un livre blanc qui traite du modèle économique de l’IA en imagerie médicale.
09/06/2026 -


Les trois principes de base de l'IA explicable
La confiance des professionnels de Santé envers l’IA commence par l’assimilation du fonctionnement des algorithmes, grâce à l’IA explicable. Les trois principes directeurs de cette méthode décrits dans un article de l’American Journal of Roentgenology (AJR), pourraient rassurer les praticiens sur la...
26/05/2026 -

Une checklist pour l'élaboration des outils d'IA en imagerie mise à jour
Si les outils et modèles d’intelligence artificielle (IA) sont aujourd’hui largement répandus, leur précision et leur robustesse sont encore inégales. Pour faire évoluer cette discipline, des documents de recommandations relatives à l’élaboration de ces outils font office de référence pour leurs aut...
03/04/2026 -

La radiologie française parle aux européens des apports de l'IA dans l'imagerie d'urgence
Vu dans la newsletter de Mars 2026 publiée par la Société Française de Radiologie (SFR), un retour sur la session “ESR meets France” qui a réuni, à l’occasion de l’European Congress of Radiology (ECR), des experts français et européens autour d’un sujet désormais central pour l’imagerie en soins aig...
01/04/2026 -

L'IA peut-elle jouer un rôle dans le burn-out des radiologues ?
L’IA peut-elle permettre de réduire le burn-out des radiologues ? Il semble que non, si l’on en croit une revue de la littérature publiée dans la Revue European Radiology, qui tente de trouver des preuves des bienfaits de l’IA sur la santé mentale des radiologues. Les chercheurs estiment qu’une meil...
30/03/2026 -

La plateforme ATLAS d'IA en radiologie intègre plus de 230 fiches de modèles
La Radiological Society of North America (RSNA) annonce la présence de plus de 230 fiches de modèles et de jeux de données concernant 31 sous-spécialités dans sa bibliothèque annotée de systèmes d'IA (ATLAS), offrant ainsi à la communauté radiologique les outils nécessaires pour rendre la recherche...
27/03/2026 -

Une solution d'aide au diagnostic validée par la FDA pour le dépistage du cancer du poumon
Median Technologies vient d'annoncer avoir obtenu l’autorisation de la FDA pour eyonis® LCS, le premier logiciel dispositif médical de détection et diagnostic basé sur l’IA pour le dépistage du cancer du poumon.
10/02/2026 -

LETTRE D'INFORMATION
Ne manquez aucune actualité en imagerie médicale et radiologie !
Inscrivez-vous à notre lettre d’information hebdomadaire pour recevoir les dernières actualités, agendas de congrès, et restez informé des avancées et innovations dans le domaine.